
LLM for Database Model Descriptors

LLM for Database Model Descriptors
Writing documentation of data models is the least fun task in engineering. It nonetheless has huge value to those making use of the data. Good human readable documentation of a database and its tables makes life easier for data analysts and data scientists.
LLM’s can help to remove some of the friction in writing the descriptors by creating a first draft that an engineer can augment or correct.
Scenario
You are part of a team that is creating tables for downstream data science and analytics. The stakeholders have asked for documentation on the tables in the database. They would like to have a human readable format to have a quicker reference of the data and their design. Your database have a number of tables and they are generally wide, so the time to complete the request is significant.
Your team is looking for a tool that will accelerate the process and allow team members to quickly return to coding which delivers valuable tables.
Solution
LLM’s are capable of taking an input and returning a summary of that input. For the scenario described, langchain and ollama used together can make a first draft of the descriptors for each table in your database.
Ollama: Ollama is open source and can be run locally. Because it is run locally, no data is exposed to a cloud service.
Langchain – SQLDatabase: Langchain is an llm tooling framework. It has a class called `SQLDatabase`
that has methods to retrieve the ddl of a particular table among other useful methods.
Code
The code makes a call to the database, in this case a sqlite database, and retrieves the ddl of a given table. The code then builds a prompt with the table information to pass ollama, using the llama3 model. The returned response is saved in a file which can be part of a review process in which the engineer augments and corrects the descriptors.
As an additional possibility, the script in the repo can turn a json response from the llm model and serialize to a pydantic model. The pydantic model can then be used in another downstream process.
Database call to retrieve table information
def get_db() -> SQLDatabase: db = SQLDatabase.from_uri("sqlite:///Chinook.db") return db def get_table_info(table_name: str, db: SQLDatabase) -> str: table_info = db.get_table_info([table_name]) return table_info
Prompt used for retrieving the text output.
Note: {table_info} is the placeholder in which the PromptTemplate will inject the table information.
prompt = ChatPromptTemplate.from_template(
"""
system:
you are a sql analyst
human:
Please fill in the following template to provide a table description:
[Table Name]: _______________________________________________________
[Column List]:
• [column1_name] - [column1_description]
• [column2_name] - [column2_description]
...
[Additional Information]:
DDL Information: {table_info}
"""
)Example Output
Here is the example of the descriptors when run on the sqlite table called Customers.
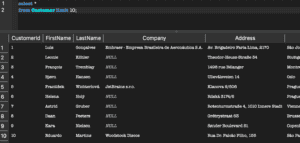
Query Result of the Customers Table
This is the data as seen in the table:
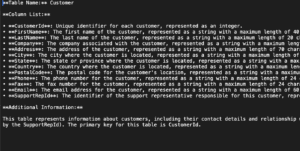
Descriptor of Customers Table
This is the descriptor when the script runs for the Customer table:
Code in Github:
https://github.com/upjohnc/langchain-database-description-application