ETL With Scala and Native SQL – Part 1

For almost as long as software engineers have been using object-oriented programming languages to access relational databases, we have been lamenting the “impedance mismatch” between the two. The lack of straightforward language constructs to allow data to move cleanly back and forth between objects and tables led to the rise of object-relational mapping tools. ORM tools provide the illusion that the programmer does not need to know SQL. But for any nontrivial data access, the ORM just obscures the engineers’ view of the native SQL of the RDBMS which they are trying to generate indirectly by manipulating JPA annotations or Spring Data method names.
Functional programming can be the solution to the impedance mismatch. It allows for the wiring between objects and tables to be expressed cleanly and concisely without the unwieldy amount of code needed for using native SQL with the JDBC API. In short, OOP + FP + SQL = Better Programs.
This requires a language that truly supports both OOP and FP, along with a database library which does not try to be an ORM. In this article we look at using Scala with the Anorm library.
Example Application
To illustrate the use of Scala and Anorm, we will build a complete extract, transform, load (ETL) application. It will extract from a simplified but otherwise typical operations database consisting of transactions for products sold in stores. That will then be transformed and loaded into a data warehouse consisting of daily sales facts with the dimensions of date, product, and store. Both of these will be in Postgres.
The following schemas represent our two databases.
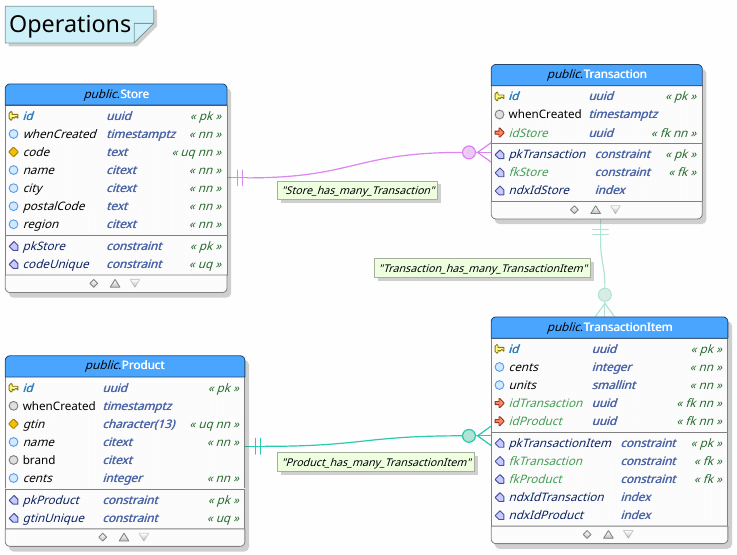
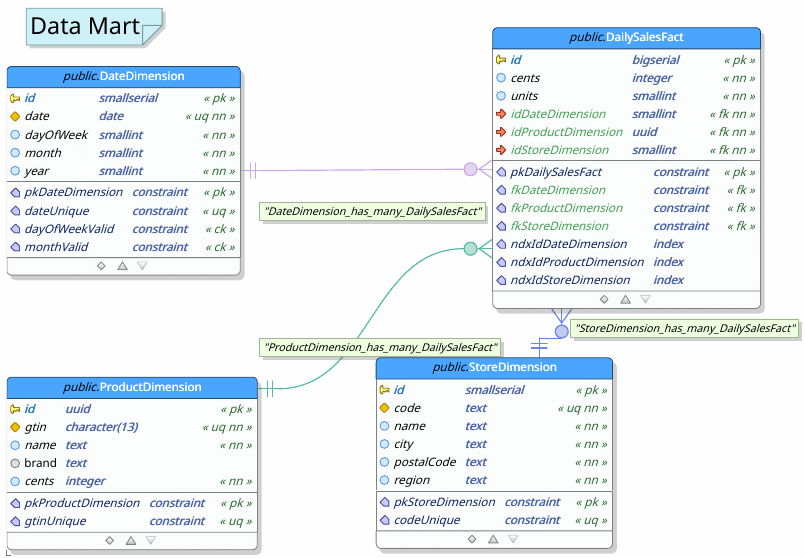

The complete source, including pgModeler files for the above ER diagrams, can be found at https://gitlab.com/lfrost/scala-etl-example.
Step 1: Write the extract query in native SQL.
Given these two schemas, we begin by writing the native SQL query to perform the extraction from the operations database. For our example application, the following query gives everything we need to populate our specified fact and dimension tables.
val Query = """
|SELECT
| sum("TransactionItem"."units") AS "units",
| sum("TransactionItem"."cents") AS "cents",
| "Transaction"."whenCreated"::date AS "date",
| EXTRACT(ISODOW FROM "Transaction"."whenCreated"::date)::int AS "dayOfWeek",
| EXTRACT(MONTH FROM "Transaction"."whenCreated"::date)::int AS "month",
| EXTRACT(YEAR FROM "Transaction"."whenCreated"::date)::int AS "year",
| "Product"."id", "Product"."gtin", "Product"."name", "Product"."brand", "Product"."cents",
| "Store"."code", "Store"."name", "Store"."city", "Store"."postalCode", "Store"."region"
|FROM "Store"
|INNER JOIN "Transaction" ON "Transaction"."idStore" = "Store"."id"
|INNER JOIN "TransactionItem" ON "TransactionItem"."idTransaction" = "Transaction"."id"
|INNER JOIN "Product" ON "Product"."id" = "TransactionItem"."idProduct"
|GROUP BY "Store"."id", "Product"."id", "date"
""".stripMargin.trim
Except for being packaged as a Scala string, the code above is completely native SQL for Postgres. Note the use of stripMargin and trim to allow our SQL to be indented appropriately for the Scala code, without the extra leading whitespace passing through to the database server. It may seem a minor thing, but anyone viewing the queries from the database server side will appreciate it.
The fact that the SQL identifiers in this example use camelCase, and so are able to match our OOP class and field names, is just a matter of consistency. It is in no way required and everything described here will work just as well with table names like TRANSACTION_ITEM.
Each resulting row of this query uniquely represents one daily sales fact plus the date dimension, product dimension, and store dimension for that fact. Each dimension value will likely appear for multiple facts, and how we handle duplicates will vary depending on the number of distinct values each dimension will have. More specifically, it will depend on whether or not a complete list of the IDs for that dimension fits comfortably in memory. For our example let’s say that the numbers of stores and dates are going to be modest, but that the number of products may be too large to maintain an in-memory list.
One other thing of note in our query is that the values extracted from the timestamp are explicitly cast to integers. This is because EXTRACT always returns a double, even when an integer value such as year is being extracted. Because the application running this will be strongly typed, it will make things cleaner to cast these in the SQL so that they become java.lang.Integer in the JDBC results. (It may seem that smallint would be more appropriate, but both end up as java.lang.Integer. See the Postgres JDBC type mapping.)
The Postgres function pg_typeof is useful for analyzing an SQL expression whose data type may not be obvious.
etl_operations=> SELECT pg_typeof(EXTRACT(MONTH FROM CURRENT_TIMESTAMP));
pg_typeof
------------------
double precision
(1 row)
Step 2: Write classes for the transformed data.
Moving to the OOP side of our equation, we define a class for each of our data warehouse tables. The transformation step of our ETL process will be to create instances of these classes from the operations query results.
case class DailySalesFact(
id : Option[Long] = None,
cents : Int,
units : Int,
idDateDimension : Option[Short] = None,
idProductDimension : Option[UUID] = None,
idStoreDimension : Option[Short] = None
)
case class DateDimension(
id : Option[Short] = None,
date : LocalDate,
dayOfWeek : DayOfWeek,
month : Month,
year : Int
)
case class ProductDimension(
id : UUID,
gtin : String,
name : String,
brand : Option[String] = None,
cents : Int
)
case class StoreDimension(
id : Option[Short] = None,
code : String,
name : String,
city : String,
postalCode : String,
region : String
)
Option in Scala is used much more heavily than Optional in Java, including for class fields as seen above, which is specifically recommended against in Java (Core Java 11, Volume II, section 1.7.4). There are two distinct cases for using Option in our model classes.
- The value represents a nullable column in the database.
- The value represents a column which is populated automatically by the database (e.g., primary keys and timestamps), so the value is not known at the time the instance is created.
Step 3: Write row parsers.
The row parsers provide the main FP wiring between the SQL query and the OOP classes. The Anorm method SqlParser.get takes a JDBC column name and type to extract that column from a query result row and map it to a field in one of our classes.
val DailySalesFactRowParser : RowParser[DailySalesFact] = {
get[Int]("cents") ~
get[Int]("units") map {
case cents ~ units =>
DailySalesFact(cents = cents, units = units)
}
}
val DateDimensionRowParser : RowParser[DateDimension] = {
get[LocalDate]("date") ~
get[DayOfWeek]("dayOfWeek") ~
get[Month]("month") ~
get[Int]("year") map {
case date ~ dayOfWeek ~ month ~ year =>
DateDimension(date = date, dayOfWeek = dayOfWeek, month = month, year = year)
}
}
val ProductDimensionRowParser : RowParser[ProductDimension] = {
get[UUID]("Product.id") ~
get[String]("Product.gtin") ~
get[String]("Product.name") ~
get[Option[String]]("Product.brand") ~
get[Int]("Product.cents") map {
case id ~ gtin ~ name ~ brand ~ cents =>
ProductDimension(id = id, gtin = gtin, name = name, brand = brand, cents = cents)
}
}
val StoreDimensionRowParser : RowParser[StoreDimension] = {
get[String]("Store.code") ~
get[String]("Store.name") ~
get[String]("Store.city") ~
get[String]("Store.postalCode") ~
get[String]("Store.region") map {
case code ~ name ~ city ~ postalCode ~ region =>
StoreDimension(code = code, name = name, city = city, postalCode = postalCode, region = region)
}
}
Just as ~ can be used to take a group of columns into a single class instance, it can also be used to merge multiple row parsers in order to take a group of columns into a tuple of class instances. A unified row parser for our example query could be constructed as follows.
val CombinedRowParser : RowParser[(DailySalesFact, DateDimension, ProductDimension, StoreDimension)] = {
DailySalesFactRowParser ~ DateDimensionRowParser ~ ProductDimensionRowParser ~ StoreDimensionRowParser map {
case dsf ~ dd ~ pd ~ sd =>
(dsf, dd, pd, sd)
}
}
Step 4: Write custom column parsers.
This step is only required if our classes include fields of unusual types. We could have made DateDimension.dayOfWeek of type Short, but in the spirit of being strongly typed we used java.time.DayOfWeek. Anorm does not know how to convert from java.lang.Integer to java.time.DayOfWeek (and it probably should not, given that there is more than one way to represent days of the week as integers), but it enables us to easily define a conversion that matches our integer representation and will then be used transparently by Anorm.
Below is a custom column parser for converting java.lang.Integer to java.time.DayOfWeek. Because we used ISODOW when extracting the day of week, our range is 1-7 for Monday through Sunday, which is as expected by the DayOfWeek.of method. This column parser uses pattern matching to validate the value and return an Either[TypeDoesNotMatch, DayOfWeek].
implicit val ColumnIntToDayOfWeek : Column[DayOfWeek] = Column.nonNull { (value, meta) =>
// Extract the column name and JDBC class name from the column meta data.
val MetaDataItem(column, nullable@_, clazz) = meta
value match {
case i : Int if (i >= 1 && i Right(DayOfWeek.of(i))
case _ => Left(TypeDoesNotMatch(s"Cannot convert $column::$clazz value $value to DayOfWeek."))
}
}
See the example source code for a similar column parser for Month, as well as one for converting the Postgres citext (case-insensitive text) type to a String.
Step 5: Execute the extract query.
Now that we have our row parser, we can use it with Anorm to run our SQL and cleanly funnel the results directly into instances of our classes.
val result = SQL(Query).
asSimple().
as(CombinedRowParser.*)
The SQL method takes our literal query in native SQL and creates an SqlQuery object. The asSimple method converts this to a SimpleSql object, on which we can call the as method to take the results of the query seamlessly into a list of tuples containing instances of our classes (in our case, the type of result is List[(DailySalesFact, DateDimension, ProductDimension, StoreDimension)]).
The value passed to as is not actually the row parser, but the result of calling the * method on our row parser. This causes as to result in a list, which may be empty. There is also a + method for non-empty lists. For queries that will return only one row, there are the methods single and singleOpt.
The call to asSimple is not actually necessary because there is an implicit conversion defined from SqlQuery to SimpleSql. I have included it here for clarity, to prevent any frustration in trying to locate an as method on SqlQuery.
There of course must be a database connection available, but other than that, this is all there is to it once we have our classes and row parsers set up. With Anorm and our concise FP wiring, the data flows easily from our tables to our classes.
In part 2 of this article we will look at streaming our extract query results, since the entire result set will not likely fit in memory, and also executing native SQL insert statements.