
Databricks Delta Live Tables: Automated Testing

Databricks Delta Live Tables: Automated Testing
On one data project that was for reporting sla’s to a partner company, an analyst misreported an SLA due to swapping the `<` with `>`. Because the comparison function should have been “less than”, the report showed always “meets SLA”. It was a simple mistake that reviewers overlooked. Also, there wasn’t solid data to test the query. It is a situation that makes working with data hard.
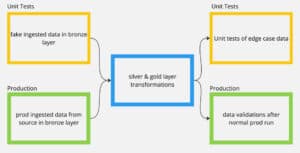
Delta Live Tables (DLT) pipelines have the same difficulty – the need to have input data that tests all known cases. Because the silver layer and gold layer can be in their own notebooks separate from the bronze layer, also known as the ingestion layer, the bronze layer can be mocked with hardcoded data in pyspark code. As the diagram shows, the bronze layer with the test data input is used in a notebook and that notebook is part of a test pipeline.
Diagram showing that the silver and gold layers are consistent between the test pipeline and the production pipeline.
Scenario
You would like to have data inputs and tests that assure the silver and gold layers are matching business requirements. The data input should be consistent for individual queries, not necessarily a whole “test” database. Additionally, you would like to have tests that build on the data inputs and are run as part of a CI/CD process. You have a defined set of silver and gold tables in your DLT notebooks that can be the basis for a test pipeline.
Solution
As shown in the code snippet below, you can define temporary tables that have the same names as the ingest tables that the silver layer and gold layer are built on. Additionally, the data can be controlled for specific business requirements through a python dict that is passed to the spark dataframe. These temporary tables are the mock of the bronze layer and are in their own notebook. Then in place of data validation notebook, you can create a notebook of unit tests, which are a temporary tables wrapped in expectations.
This test pipeline is similar to a unit test suite in other software engineering disciplines. The silver and gold layer can be worked on in the normal iterative dev process. The test cases that are around these layers have the pattern of given/when/then. The input data is the given, the when is the run of the silver and gold layer, and the then is the expectation definitions.
The test pipeline can be run manually as a DLT pipeline in Databricks. It also can be part of a CI/CD process. Databricks cli has a function called `bundle` that allows you to create, deploy, and tear down DLT pipelines. This gives the engineer the power to have the tests run without manually touching the console and without leaving cruft of test pipelines behind. In the example Github action below, the DLT pipeline is only run when the pr is merged into `master`. This does two things. First, it keeps the cost down by not running on each commit push to the pr. And second, when the pipeline fails then the merge fails and the engineer can rework his pr to fix the failure.
Code
This is an example of mocking out a bronze table. The python dict is created with defined input data to test particular business rules, such as handling nulls in the CustomerID.
customer_data = [
{"CustomerID": "invalid_id", "CustomerName": "Big Name"},
{"CustomerID": None, "CustomerName": "Nice Name"},
{"CustomerID": 1, "CustomerName": "A"},
{"CustomerID": 2, "CustomerName": "Mr Smooth"},
{"CustomerID": 4, "CustomerName": "Mr Hammond"},
]
@dlt.table(
comment="Fake data of customers for testing",
temporary=True,
)
def customer_bronze():
return spark.createDataFrame(customer_data).withColumn(
"load_time", F.current_timestamp()
)Expectation to confirm that the customer_id has no null values.
CREATE TEMPORARY LIVE TABLE TEST_customer_silver(
CONSTRAINT no_nulls EXPECT(null_id = 0) ON VIOLATION FAIL UPDATE
-- length_id should be zero, force failure to show github action functionality
, CONSTRAINT length_greater_than_1 EXPECT(length_id = 1) ON VIOLATION FAIL UPDATE
)
WITH customer_id_null AS (
SELECT
count(*) AS row_count
FROM
LIVE.customer_silver
WHERE
customer_id IS NULL),
customer_id_length AS (
SELECT
count(*) AS row_count
FROM
LIVE.customer_silver
WHERE
len(customer_id) > 1
)
SELECT
customer_id_null.row_count AS null_id
, customer_id_length.row_count AS length_id
FROM
customer_id_null
, customer_id_length;
Snippet from the github action
Full github action: url for github action code
pipeline_integration_test:
name: "Run pipeline unit test"
runs-on: ubuntu-latest
# Run the "deploy" job first.
needs:
- dbx-deploy
steps:
# Check out this repo, so that this workflow can access it.
- uses: actions/checkout@v4
# Use the downloaded Databricks CLI.
- uses: databricks/setup-cli@v0.218.1
# Run the Databricks workflow named "my-job" as defined in the
# bundle that was just deployed.
- run: databricks bundle run unit_test --full-refresh-all
working-directory: .
env:
DATABRICKS_TOKEN: ${{ secrets.SP_TOKEN }}
DATABRICKS_BUNDLE_ENV: dev
Github Reference
Full code is at: URL for Github Repo of Code