
Creating a Digital Personal Assistant – Part 1

Overview
Lately, I’ve been toying with the idea of building my own digital personal assistant, leveraging AI, LLMs, and agent-based technologies. The goal is to create a tool that can help with the types of one-off tasks that people like me often encounter. This blog series isn’t meant to be a step-by-step guide but rather a walk-through of my journey, highlighting the thought process, challenges, and solutions along the way. I’ll include code snippets and, once complete, share the GitHub repository for those interested in exploring or contributing. However, it won’t be a ready-to-use tutorial; instead, it’s an exploration of what’s possible.
To kick things off, I’ve outlined a high-level wish list of features that I envision for this assistant:
- DIY Approach: I want to build it from scratch using open-source, off-the-shelf technologies. This isn’t about simply creating a custom agent in ChatGPT; it’s about crafting something truly my own.
- Flexible Interaction: I’d like the assistant to support multiple interaction methods—keyboard, voice, and more—to fit different scenarios and preferences.
- Natural Language Interaction: Communicating with the assistant should feel as natural as chatting with a friend. I don’t want to rely on memorizing specific commands or syntax.
- Project Organization: It should help me organize my tasks and interactions into projects, providing a structured way to manage my activities.
- Expandable with Plugins: A plugin-based architecture is essential so that its capabilities can grow and evolve easily over time.
- Local Operation: To minimize reliance on third-party services, I want the assistant to run locally as much as possible, ensuring greater control and privacy.
This blog post marks the beginning of a series where I’ll document the journey of bringing this digital assistant to life. Feel free to follow along and let me know your thoughts!
Foundational Technology Selection
I have a strong affinity for Python, which is fortunate given that many AI, LLM, and ML tools are either built in Python or offer excellent compatibility with it. For the AI/LLM engine, I’ll be utilizing Ollama, along with models that best fit the specific challenges I aim to tackle. To start, I’ll focus on Llama 3.2 due to its robust capabilities, compact size, and swift response times, making it a versatile choice for a wide range of tasks.
This blog post assumes you are an experienced Python developer, familiar with the basics of AI and machine learning libraries. I won’t be covering Python fundamentals, so a solid understanding of the language is recommended for following along.
Flexible Interaction
In this first post, I’ll outline how I plan to enable interaction with the assistant through both keyboard and voice input, as well as how I’ve organized the code to support these features. I’ve decided to name the assistant “Bentley” after our family dog. More than any pet I’ve had, Bentley is always eager to help and be a good companion. In honor of his helpful nature, I’m naming this project after him.
To get started, I’ve structured Bentley’s code as follows:
- main.py: This is the main entry point of the application. Running this file will start the assistant.
- bentley.py: This file contains the core logic for the AI agents we’ll be developing.
- command_io.py: This is where the code for handling user input and output will reside.
When a user runs main.py, it will initiate the application and use command_io.py to handle user input and output. The input will then be passed to bentley.py for processing, and the results will be returned to command_io.py to deliver the output back to the user.
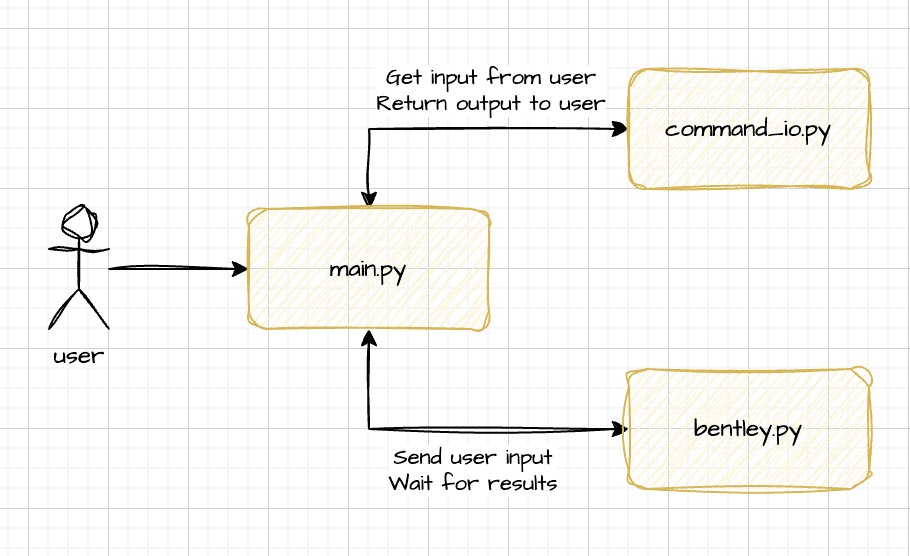
Inmain.py, I’ll use the argparse library to process command-line arguments. One key argument will be --input, which can have two options: stdio or voice. If the user selects stdio, the assistant will run as a console application, allowing interaction through typed commands. If voice is selected, the assistant will use the computer’s microphone and speakers, enabling voice-based interaction.
Here’s what main.py looks like right now:
"""Bentley Main Module - Used to kick off system."""
__version__ = '0.1.0'
from argparse import ArgumentParser
from command_io import StdioCommandIO, AudioCommandIO, CommandIO
from bentley import Bentley, Task
def run_bentley(user_io: CommandIO) -> None:
bentley = Bentley(user_io)
while True:
cmd = user_io.get_input()
activity = bentley.get_activity(cmd)
if activity.task is Task.QUIT:
break
bentley.do_activity(activity)
user_io.report_output("Ok. Goodbye.")
if __name__ == '__main__':
parser = ArgumentParser(description=f"Bentley version {__version__}")
parser.add_argument("--input", help="IO Method", choices=["voice", "stdio"], required=True)
args = parser.parse_args()
run_bentley(StdioCommandIO() if args.input == 'stdio' else AudioCommandIO())
As you might be able to surmise from the code, I’ve opted to create an abstract base class called CommandIO and two concrete subclasses: StdioCommandIO and AudioCommandIO.
For now, let’s keep CommandIO as simple as possible.
class CommandIO(ABC):
@abstractmethod
def get_input(self, prompt: str = None) -> str:
"""Retrieve command input from user"""
@abstractmethod
def report_output(self, output: str) -> None:
"""Respond to the user"""
As you can see, there are only two methods: get_input and report_output. We can expand this later as our needs change. As a result, the StdioCommandIO implementation is pretty straightforward.
class StdioCommandIO(CommandIO):
"""Console-based input/output"""
def get_input(self, prompt="Command") -> str:
try:
return input(f"{prompt} > ")
except (EOFError, KeyboardInterrupt):
print("quit")
return "quit"
def report_output(self, output: str) -> None:
print(output)
For the AudioCommandIO implementation things are going to be a little more involved. I need to solve for two problems:
- Unlike just using Python’s built-in
inputfunction, I have to receive the user input via a microphone. This involves recording audio and then translating that audio into text. - Conversely, I can’t just use the
printfunction to send output to the users. I have to convert text into audio and play it on the computer’s speaker.
Audio Input
After evaluating several options, I found that Google’s speech recognition, accessed through the Python speechrecognition package, offered the most hassle-free and flexible implementation. One of the advantages is that I don’t even need to provide an API key or set up any additional configuration—everything works out of the box. While this choice deviates from my goal of running everything locally, I couldn’t find a truly local solution with the necessary quality to make the tool genuinely usable. However, if Google’s service becomes unsuitable in the future, I can easily switch to another solution, as the speechrecognition package supports a variety of recognizers.
Here’s what the get_input implementation looks like:
class AudioCommandIO(CommandIO):
"""Microphone/speaker-based input/output"""
UNRECOGNIZABLE_AUDIO = "unrecognized audio"
def __init__(self):
self.recognizer = speech_recognition.Recognizer()
def get_input(self, prompt='What would you like to do?') -> str:
if prompt:
self.report_output(prompt)
with speech_recognition.Microphone() as mic:
self.recognizer.adjust_for_ambient_noise(mic)
phrase = self.recognizer.listen(mic)
while True:
try:
text = self.recognizer.recognize_google(phrase)
print(f"I heard: {text}", file=sys.stderr)
return text
except speech_recognition.UnknownValueError:
return self.UNRECOGNIZABLE_AUDIO
except speech_recognition.RequestError as e:
print(f"Error: {e}")
return self.UNRECOGNIZABLE_AUDIO
Audio Output
For audio output, again, I reviewed a number of technologies, but landed on a Google solution: gtts. It’s also cost and hassle free to implement and doesn’t require an API key. While gtts will translate the text to audio, it doesn’t play it on the speaker. To do that I use combination of pyaudio and pydub. Here’s what the report_output implementation looks like:
def report_output(self, output: str) -> None:
mp3_fp = BytesIO()
tts = gTTS(output, lang="en", slow=False)
tts.write_to_fp(mp3_fp)
mp3_fp.seek(0)
audio_segment = AudioSegment.from_file(mp3_fp, format="mp3")
pcm_data = audio_segment.raw_data
pa = PyAudio()
stream = pa.open(
format=pa.get_format_from_width(audio_segment.sample_width),
channels=audio_segment.channels,
rate=audio_segment.frame_rate,
output=True
)
stream.write(pcm_data)
stream.stop_stream()
stream.close()
Wrapping Up
That’s all for this first installment! To recap, we’ve covered:
- The high-level requirements and goals for the digital personal assistant
- An overview of the initial architecture
- The technology stack selection
- Approaches for flexible user input and output
In the next blog entry, we’ll dive into creating an agent that can interpret user input, translate it into actionable requests, and determine how to respond effectively. Stay tuned for more on bringing this assistant to life!
Here’s a link to the full listing of command_io.py.